Enterprise localization is currently facing a structural “blind spot.” For decades, the industry has revolved around Translation Memory (TM)—a system designed to find matches based on how similar a new sentence is to a previous one.
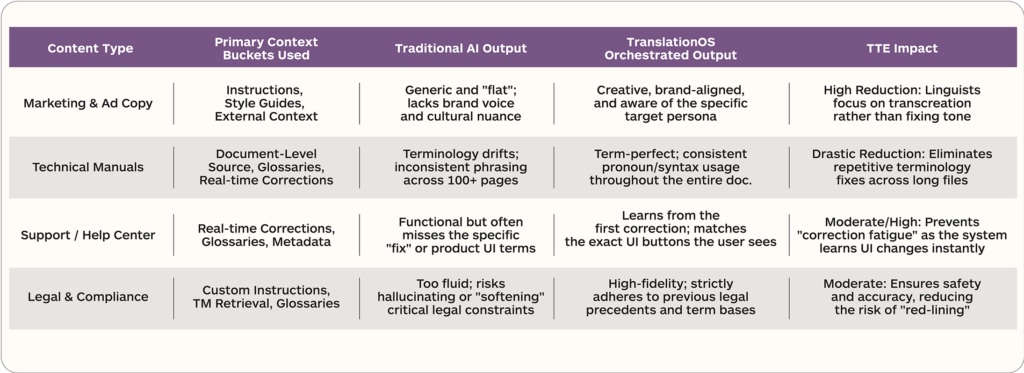
While TM was a breakthrough thirty years ago, it is insufficient for the AI era. Modern AI doesn’t just need strings; it needs context. Without it, you get output that is technically correct but tonally “off,” terminologically inconsistent, and disconnected from your brand’s unique voice.
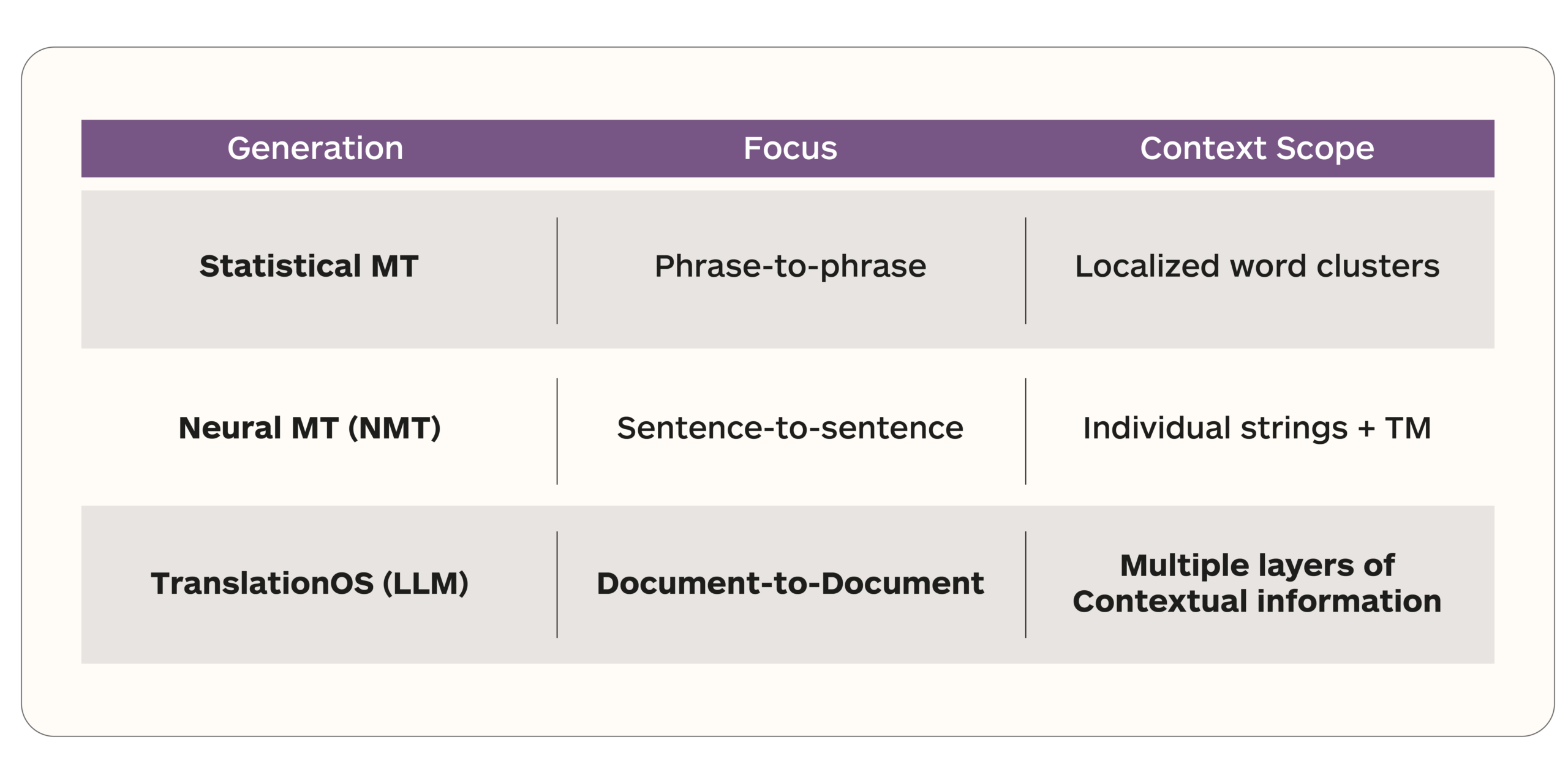
The standard workflow looks like this: content goes into a translation management system, gets segmented, matched against a translation memory, routed to a translator or a machine translation engine, reviewed, and delivered. This process was designed decades ago around a simple idea: the most valuable asset in localization is the translation memory. Every tool, every workflow, every pricing model in the industry is built around TM leverage.
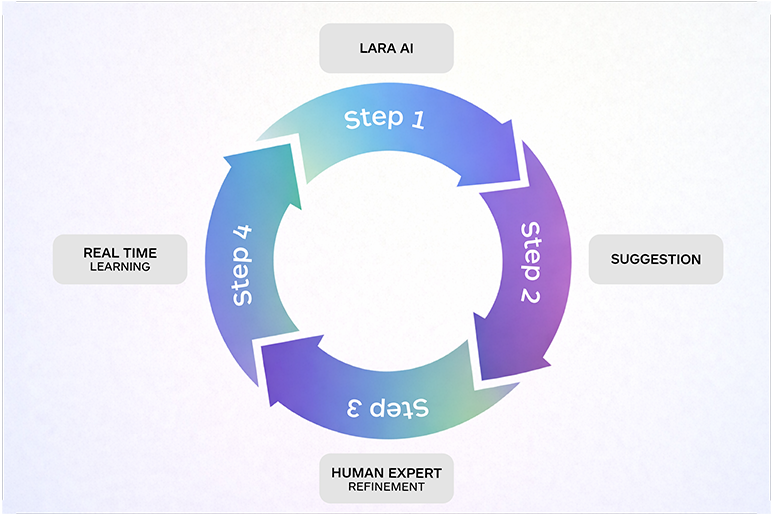
The problem is that AI does not work the way translation memory does. TM gives you a match based on how similar a new sentence is to one you have translated before. AI needs something fundamentally different. It needs context. Not just what this sentence looks like, but what it means, where it lives, what came before it, what brand it represents, how formal it should be, and what terminology is non-negotiable. Feed AI a source segment and a TM match, and you get output that is technically translated but tonally inconsistent, terminologically unreliable, and blind to everything that makes a brand sound like itself.
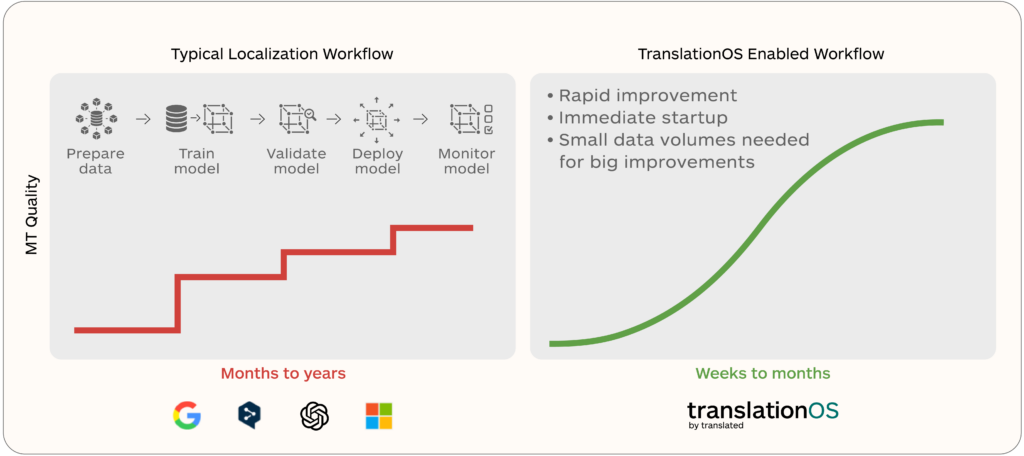
This is the wall most enterprises hit when they adopt AI translation. The technology works. The results do not meet expectations. Translators spend their time compensating for what the technology misses, and leadership cannot see clearly enough into the process to understand what is happening, what it costs, or whether it is improving.