Time to Edit as a KPI for MT quality
Over the years, Translated has continually worked to evaluate and monitor machine translation quality. In 2011, we finally standardized our methodology and settled on a metric we call “Time to Edit,” the time required by the world’s highest-performing professional translators to check and correct MT-suggested translations. Since then, we've been tracking the average Time to Edit (TTE) per word in the source language.
Time to Edit is calculated as the total time that a translator spends post-editing a segment of text divided by the number of words making up that segment. We consider TTE the best measure of translation quality as there is no concrete way to define it other than measuring the average time required to check and correct a translation in a real working scenario.
Averaged over many text segments, TTE gives an accurate estimate with low variance. Machine translation researchers have not yet had the opportunity to work with such large quantities of data collected from production settings. It is for this reason that they have had to rely on automated estimates such as the edit distance, or the number of operations required to make a correction.
By switching from automated estimates to measurements of human cognitive effort, we reassign the quality evaluation to those traditionally in charge of the task: professional translators.
Thus, a sentence with a single character mismatch that requires significant translator time to understand and correct the mismatch would not receive an unduly high-quality estimation. Metrics like Edit Distance and BLEU (Bilingual Evaluation Understudy) would miss the need for the special cognitive effort needed for such corrections and tend to inflate quality estimations.
Additionally, both edit distance and semantic difference scores cannot be used as a consistent and accurate indication of MT quality in a production scenario. Consistent scoring and quality measurement are challenging in the production scenario because this is greatly influenced by varying content type, translator competence, and turnaround time expectations. These factors are not considered by the aforementioned methods.
In over 20 years of business, Translated has gathered evidence that TTE is a much more reliable indicator of progress in MT quality than automated metrics like BLEU or COMET (Crosslingual Optimized Metric for Evaluation of Translation), as it represents a more accurate approximation of the cognitive effort required to correct a translation.
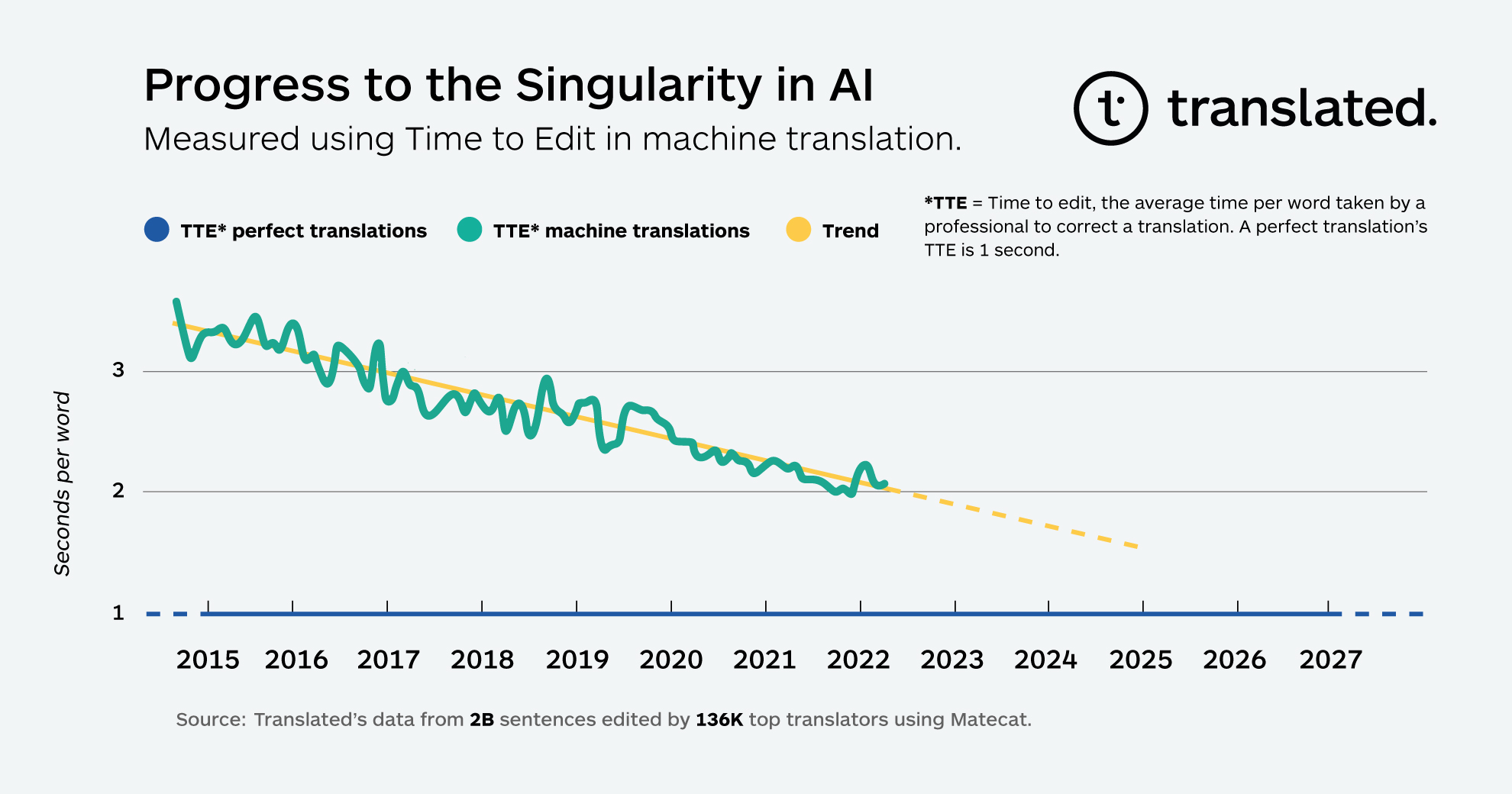
According to data collected across billions of segments, TTE has been continuously improving since Translated started monitoring it as an operational KPI.
When plotted graphically, the TTE data shows a surprisingly linear trend. If this trend in TTE continues its decline at the same rate as it has since 2014, TTE is projected to decrease to one second within the next several years, approaching a point where MT would provide what could be called “a perfect translation.” This is the point of singularity at which the time top professionals spend checking a translation produced by the MT is not different from the time spent checking a translation produced by their colleagues which doesn't require any editing. The exact date of when this point will be reached may vary, but the trend is clear.
Our initial hypothesis to explain the surprisingly consistent linearity in the trend is that every unit of progress toward closing the quality gap requires exponentially more resources than the previous unit, and we accordingly deploy those resources: computing power (doubling every two years), data availability (the number of words translated increases at a compound annual growth rate of 6.2% according to Nimdzi Insights), and machine learning algorithms’ efficiency (computation needed for training, 44x improvement from 2012-2019, according to OpenAI).
Another surprising aspect of the trend is how smoothly it progresses. We expected drops in TTE with every introduction of a new major model, from statistical MT to RNN-based architectures to the Transformer and Adaptive Transformer. The impact of introducing each new model has likely been distributed over time because translators were free to adopt the upgrades when they wanted.