Rome – August 8, 2024
With the advent of Large Language Models (LLMs), there are exciting new possibilities available. However, we also see a large volume of mostly vague and poorly defined claims of "using Al" by practitioners with little or no experience with machine learning technology and algorithms. The signal-to-noise (hype-to-reality) ratio has never been higher, and much of the hype fails to meet real business production use case requirements. Aside from the data privacy issues, copyright problems, and potential misuse of LLMs by bad actors, hallucinations and reliability issues also continue to plague LLMs.
Enterprise users expect production IT infrastructure output to be reliable, consistent, and predictable on an ongoing basis, but there are very few use cases where this is currently possible with LLM output. The situation is evolving, and many expect that the expert use of LLMs could have a dramatic and favorable impact on current translation production processes.
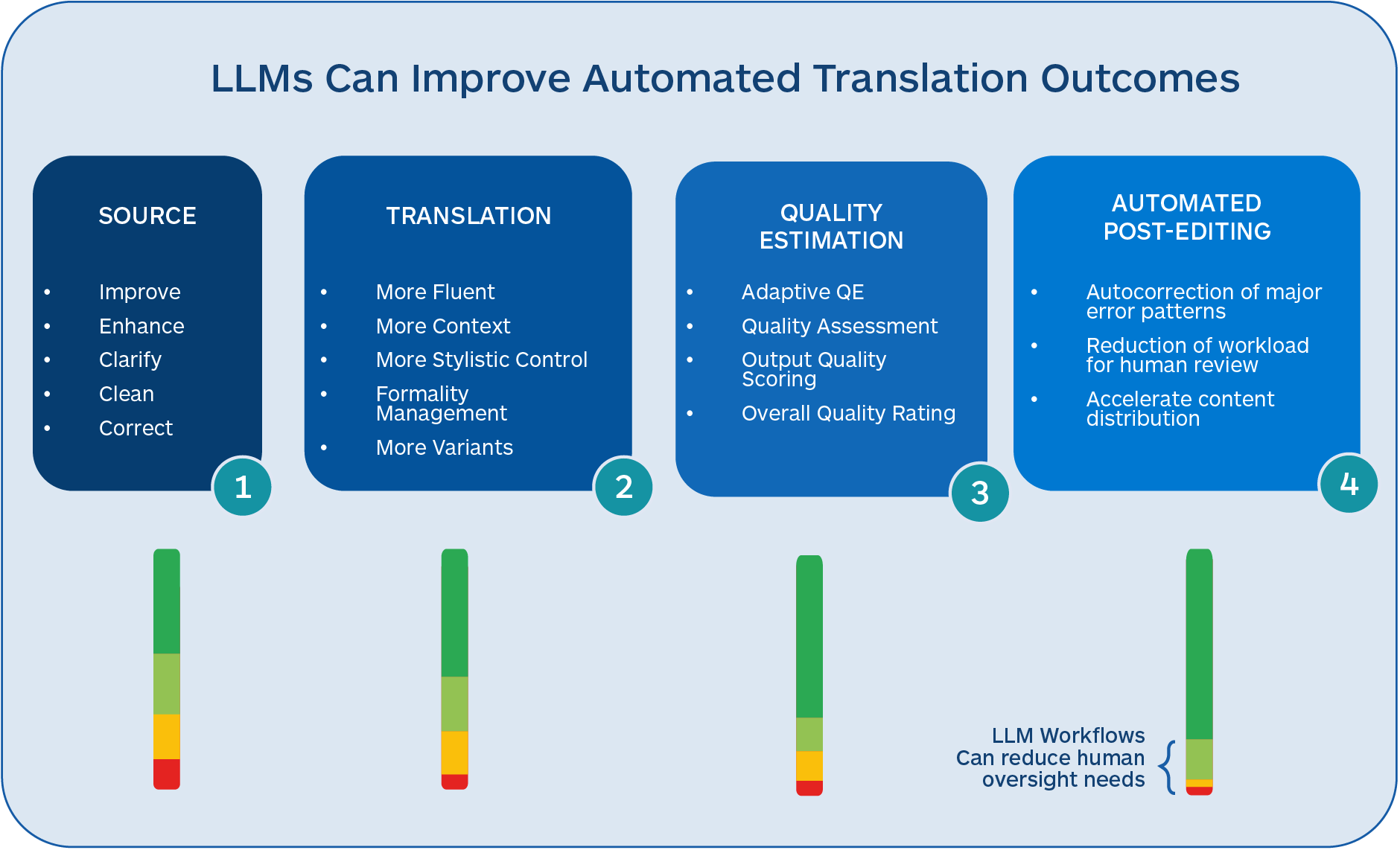
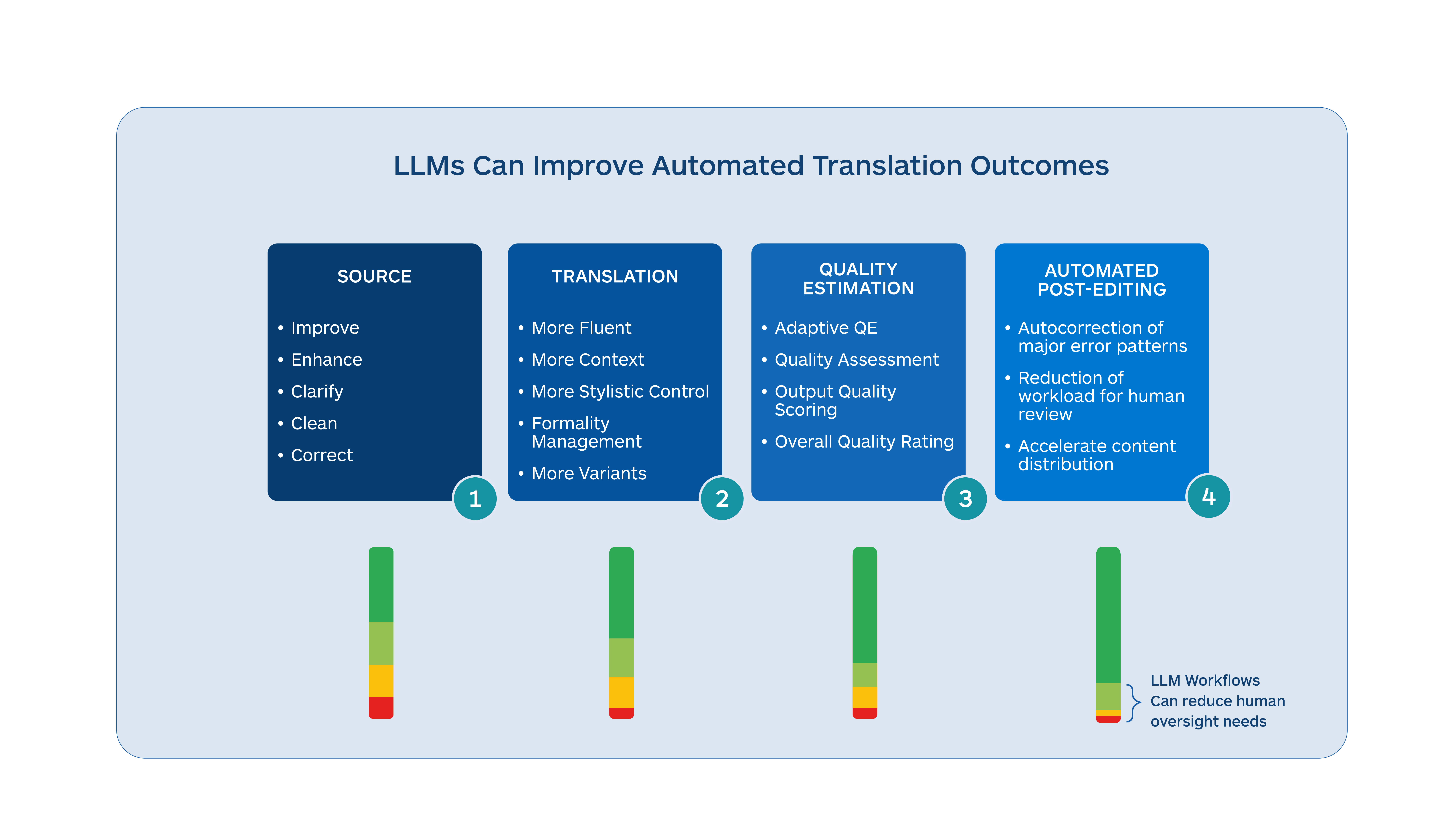
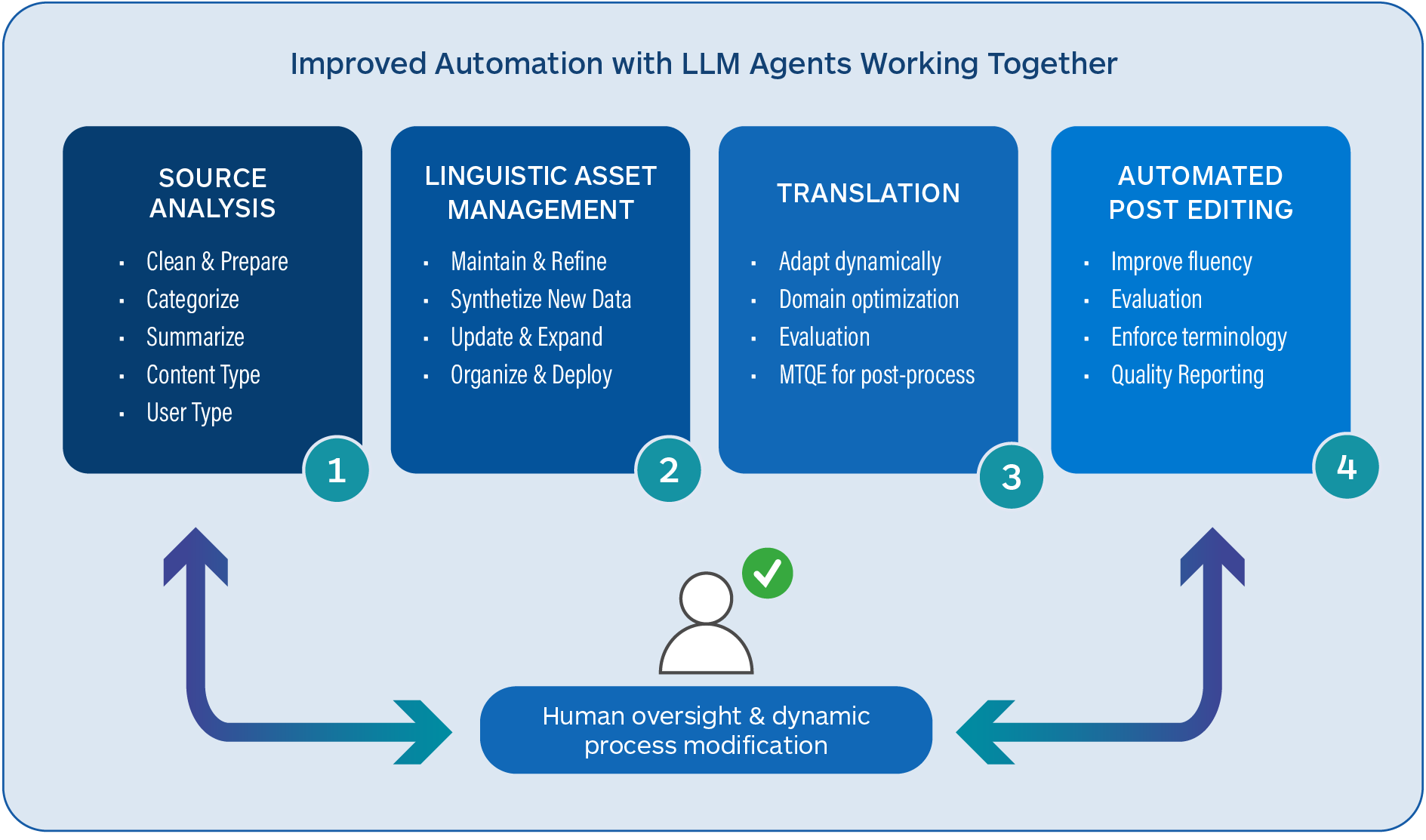
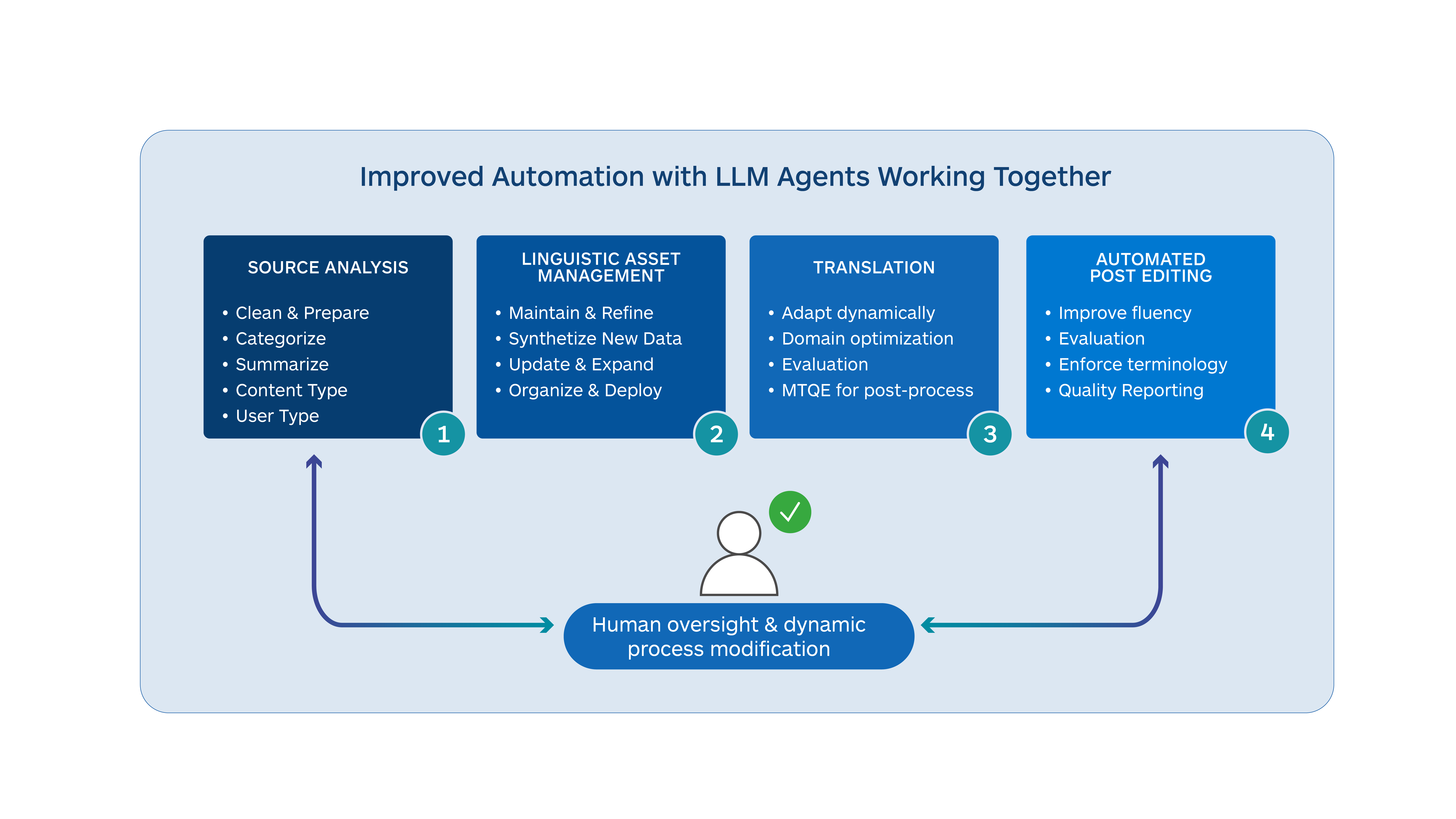
There are several areas in and around the machine translation task where LLMs can add considerable value to the overall language translation process. These include the following:
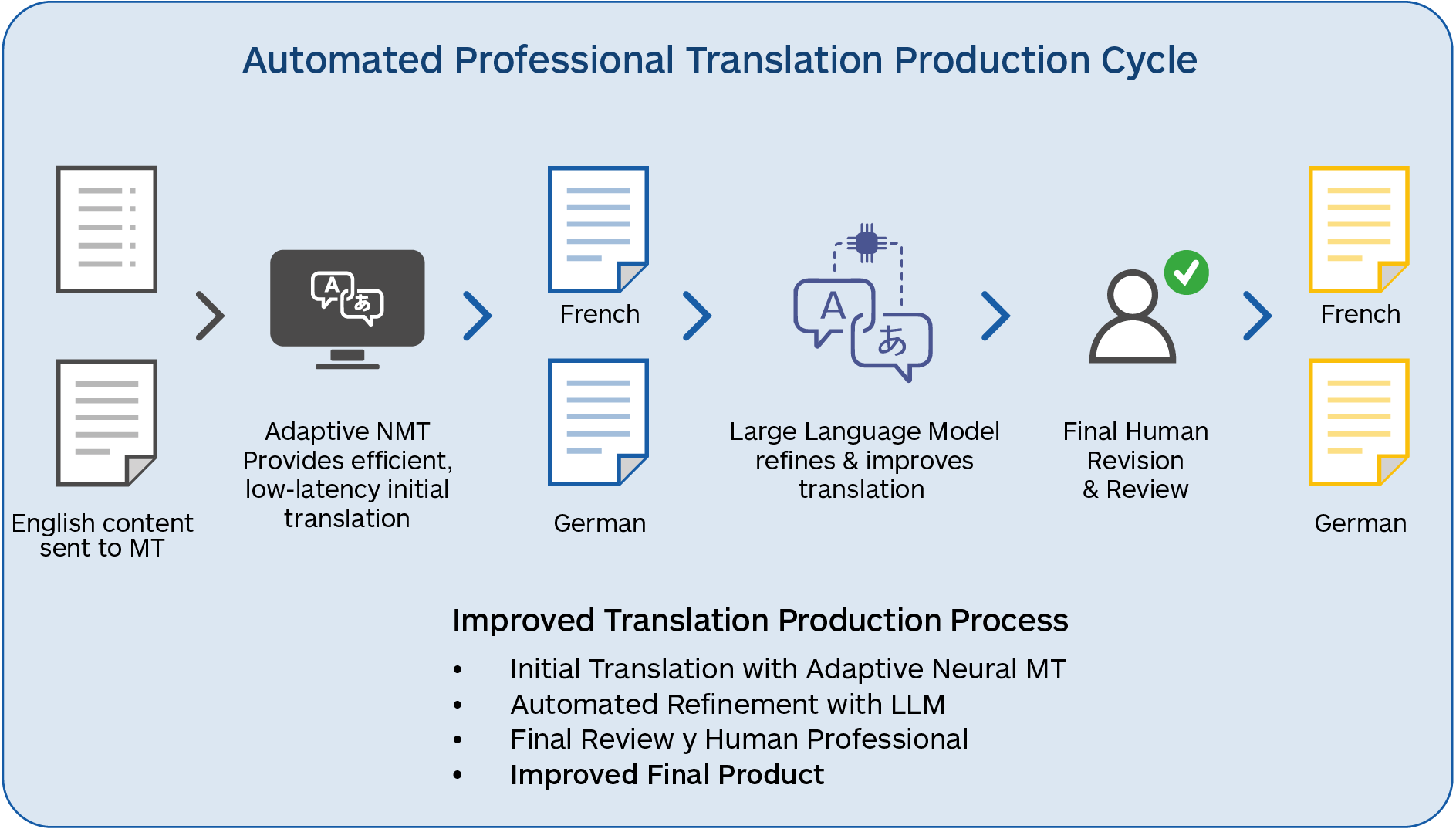
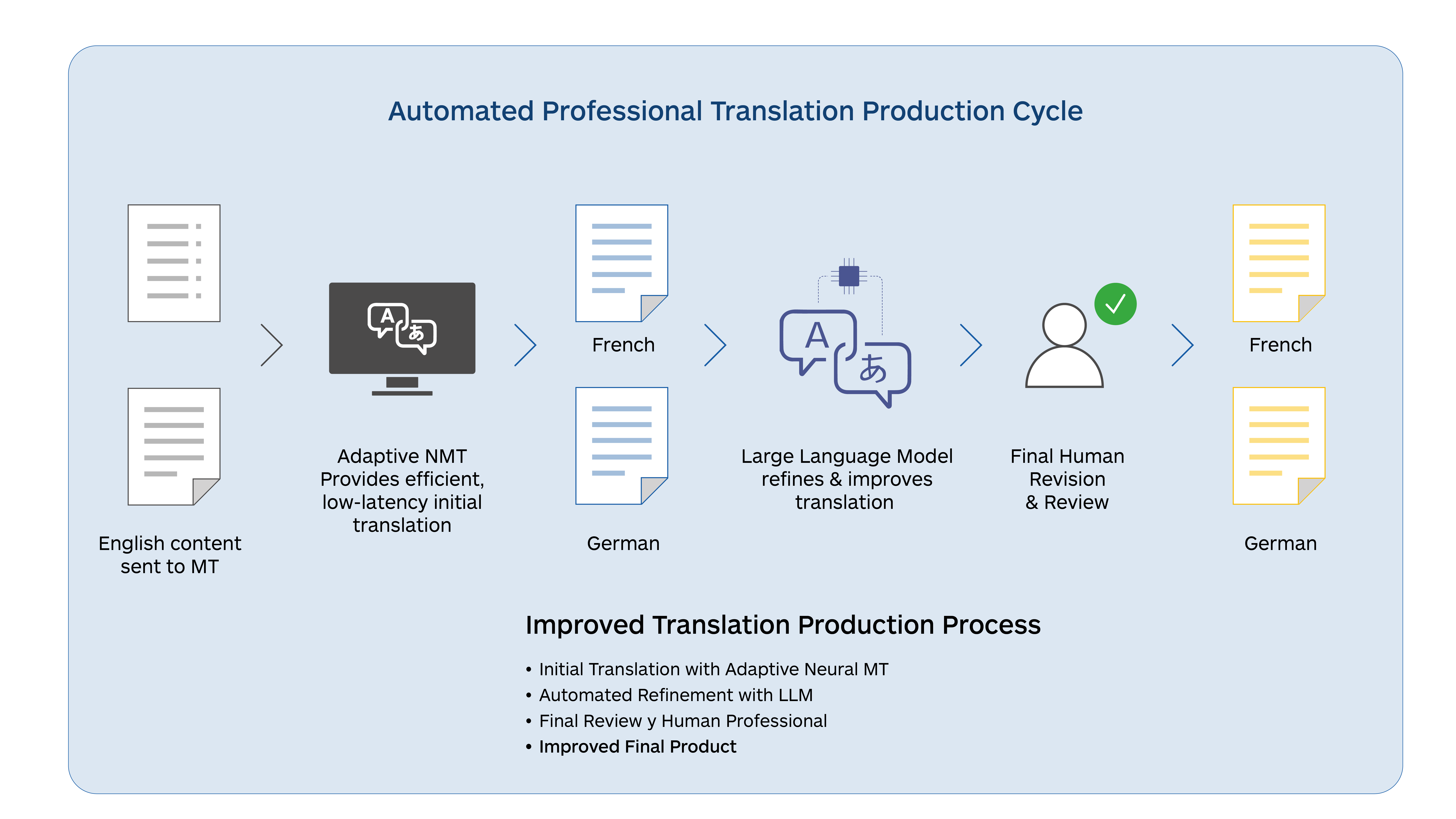
- LLM translations tend to be more fluent and acquire more contextual information, albeit in a smaller set of languages
- Source text can be improved and enhanced before translation to produce better-quality translations
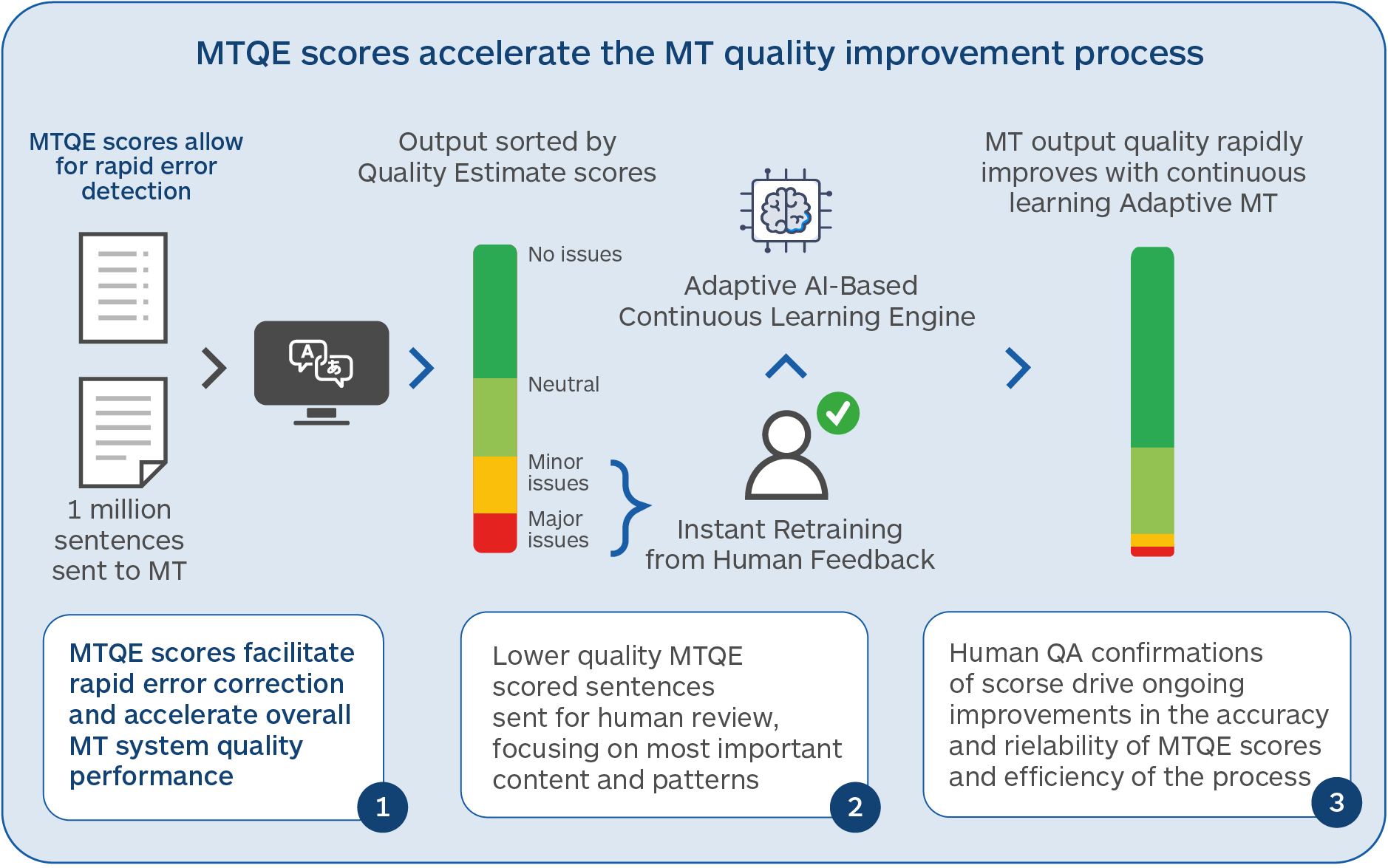
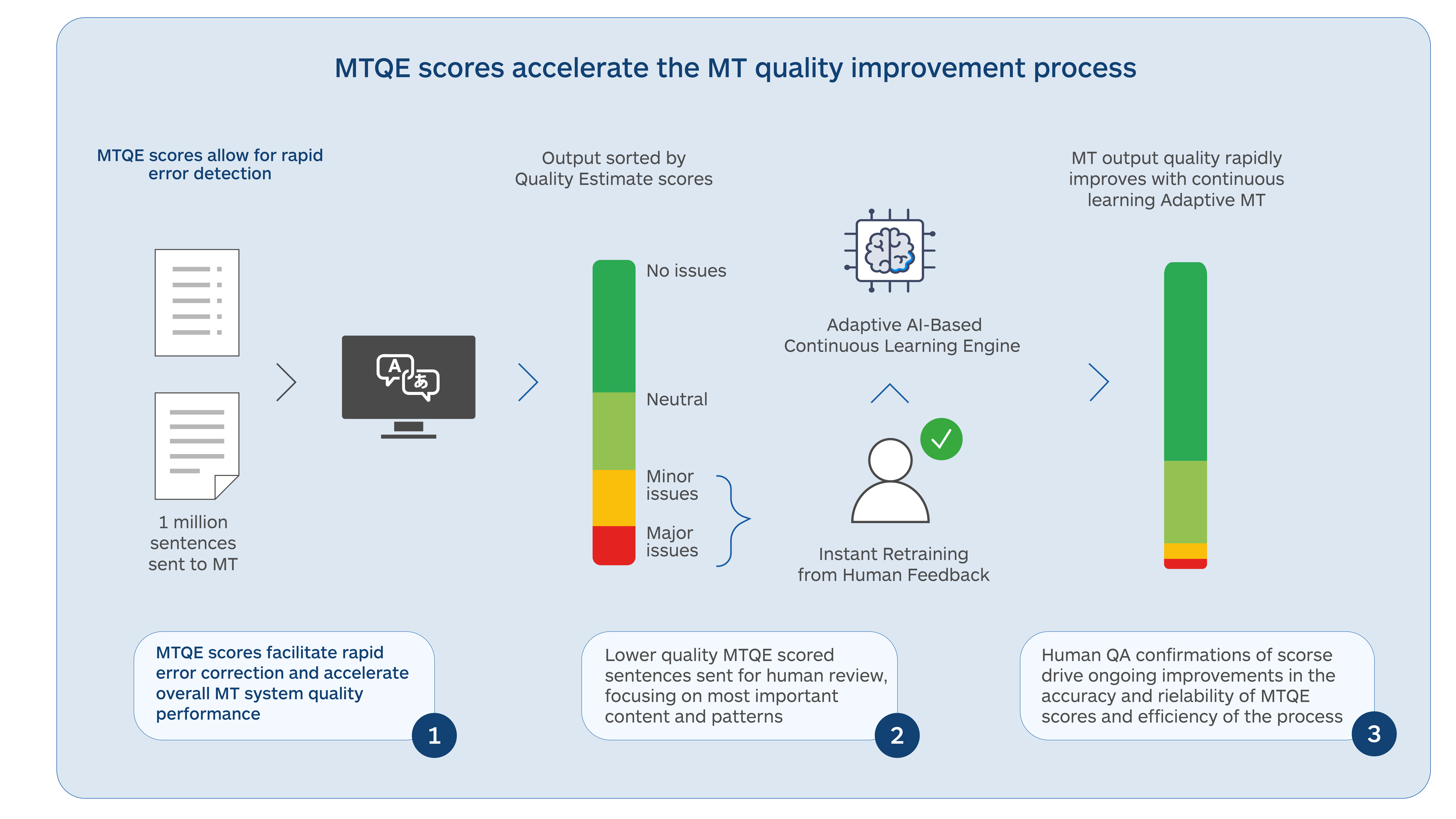
- LLMs can carry out quality assessments on translated output and identify different types of errors
- LLMs can be trained to take corrective actions on translated output to raise overall quality
- LLM MT is easier to adapt dynamically and can avoid the large re-training that typical static NMT models require