Bemutatkozik a Lara
Vezérigazgatónk, Marco Trombetti bemutatta a Larát, több mint 15 évnyi gépi fordítási kutatásunk csúcspontját. 2011-ben úttörő szerepet játszottunk az adaptív gépi fordításban. 2017 óta működtetjük a neurális gépi fordítási rendszerünket a Transformer modellel, amelyet fordításra találtak ki, és később a generatív MI alapjává vált. A ChatGPT megjelenése után a nagy nyelvi modellek nagyon népszerűek lettek. Az embereket lenyűgözte a nyelvi folyékonyságuk és a nagy kontextusok kezelésére való képességük, ugyanakkor a pontatlanságuk csalódást keltett. Mi már akkor gőzerővel azon dolgoztunk, hogy a nagy nyelvi modellek erejét a gépi fordítás pontosságával ötvözzük. Ma pedig büszkék vagyunk arra, hogy elértük ezt a mérföldkövet, és a két képességet kombinálva megalkottuk a Larát, a világ legjobb fordítási MI-jét.
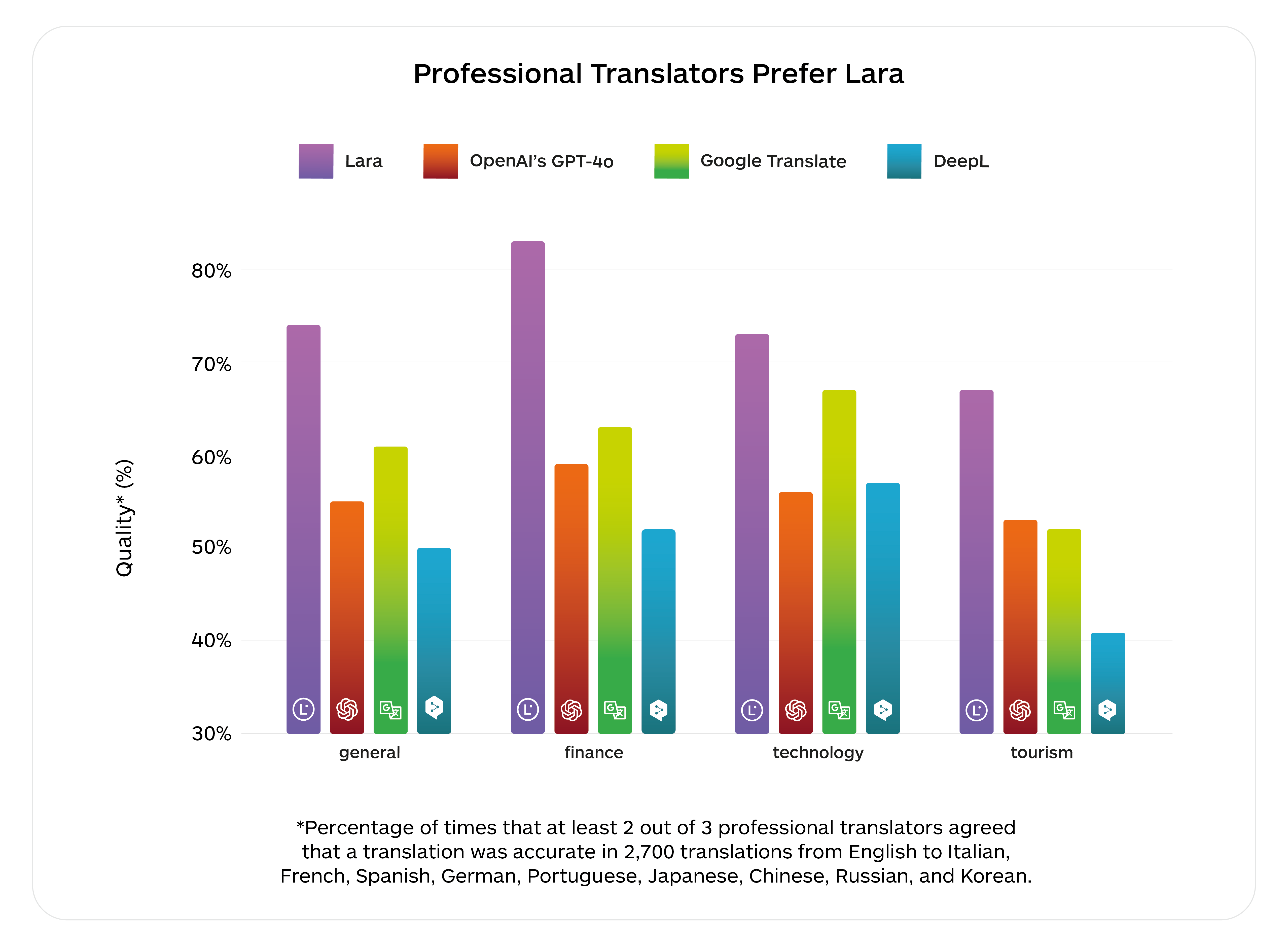
A Lara új szintet jelent a gépi fordításban, mert magyarázatot ad a döntéseihez, amihez a kontextus ismeretét és az érvelést használja, így professzionális minőségű fordításokat képes létrehozni, amelyekben a felhasználók megbízhatnak. A világszinten elérhető legnagyobb, legjobban gondozott, valós fordítási adatkészletre alapoz. Az NVIDIA-val való hosszú távú együttműködésünknek köszönhetően a Larát 1,2 millió GPU-órán keresztül tanítottuk az NVIDIA MI-platformján.
A Larával a vállalatok korábban elképzelhetetlen lokalizációs projekteket kezelhetnek. A fordítók és a többnyelvű alkotók élvezni fogják a Lara képességeit a mindennapi munkájuk során, amelyekkel új szintre emelhetik a termelékenységüket és pontosságukat.
A Lara hibaaránya ezer szavanként mindössze 2,4 hiba. 2025-ben még nagyobb célt tűztünk ki magunk elé: terveink szerint 20 millió GPU-órát használunk fel, hogy még közelebb kerüljünk a nyelvi szingularitáshoz.